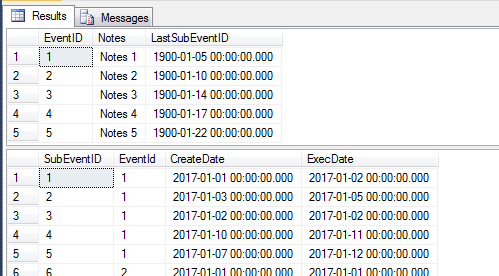
In the demo:
Events and SubEvents tables.
LastSubEventID in Events table is the subevent of the last CreateDate of the SubEvents of the event.
We want to update LastSubEventID to be according to the the subevent of the last ExecDate of the SubEvents of the event.
-- 1. Create the demo tables:
CREATE TABLE dbo.Events
(
EventID int,
Notes nvarchar(50),
LastSubEventID datetime
)
GO
CREATE TABLE dbo.SubEvents -- in the real life - join of 3-4 tables
(
SubEventID int,
EventId int,
CreateDate datetime,
ExecDate datetime
)
GO
INSERT INTO dbo.Events (EventID, Notes)
VALUES (1, 'Notes 1'), (2, 'Notes 2'), (3, 'Notes 3'), (4, 'Notes 4'), (5, 'Notes 5')
GO
INSERT INTO dbo.SubEvents (SubEventID, EventID, CreateDate, ExecDate)
VALUES
(1, 1, '2017-01-01', '2017-01-02'),
(2, 1, '2017-01-03', '2017-01-05'),
(3, 1, '2017-01-02', '2017-01-02'),
(4, 1, '2017-01-10', '2017-01-11'),
(5, 1, '2017-01-07', '2017-01-12'),
(6, 2, '2017-01-01', '2017-01-01'),
(7, 2, '2017-01-02', '2017-01-02'),
(8, 2, '2017-01-03', '2017-01-03'),
(9, 2, '2017-01-04', '2017-01-04'),
(10, 3, '2017-01-01', '2017-01-06'),
(11, 3, '2017-01-02', '2017-01-15'),
(12, 3, '2017-01-06', '2017-01-11'),
(13, 3, '2017-01-08', '2017-01-12'),
(14, 4, '2017-01-05', '2017-01-11'),
(15, 4, '2017-01-03', '2017-01-11'),
(16, 4, '2017-01-22', '2017-01-11'),
(17, 4, '2017-01-01', '2017-01-11'),
(18, 4, '2017-01-10', '2017-01-11'),
(19, 5, '2017-01-11', '2017-01-21'),
(20, 5, '2017-01-01', '2017-01-11'),
(21, 5, '2017-01-22', '2017-01-23'),
(22, 5, '2017-01-03', '2017-01-03'),
(23, 5, '2017-01-02', '2017-01-07')
GO
Starting point: LastSubEventID is the subevent of the last CreateDate of the SubEvents of the event.
UPDATE dbo.Events SET LastSubEventID = 4 WHERE EventID = 1
UPDATE dbo.Events SET LastSubEventID = 9 WHERE EventID = 2
UPDATE dbo.Events SET LastSubEventID = 13 WHERE EventID = 3
UPDATE dbo.Events SET LastSubEventID = 16 WHERE EventID = 4
UPDATE dbo.Events SET LastSubEventID = 21 WHERE EventID = 5
SELECT * FROM dbo.Events
SELECT * FROM dbo.SubEvents
Now we want to update LastSubEventID to be according to the the subevent of the last ExecDate of the SubEvents of the event.
-- 2. Get the last sub-events according to the 2 options:
SELECT DISTINCT
e.EventID,
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
-- 3. Now join them to the event table and select only the required results (= what we need to change):
; WITH maxes AS
(
SELECT DISTINCT
e.EventID,
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
SELECT *
FROM dbo.Events e
JOIN maxes ON e.EventID = maxes.EventID
WHERE e.LastSubEventID <> maxes.maxEventId_ExecDate
-- 4. but, actually we don't need maxEventId_CreateDate, so let's remove it from the query and help the SQL to run better abd faster:
; WITH maxes AS
(
SELECT DISTINCT
e.EventID,
--FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
SELECT *
FROM dbo.Events e
JOIN maxes ON e.EventID = maxes.EventID
WHERE e.LastSubEventID <> maxes.maxEventId_ExecDate
Why the results are different?????
In the "real world", I had more then 1,800,000 records,
and the results count was 40,000 instead of 4,000.....
So I tried to understand why the numbers of the queries are so differents.
-- 5. First check: what are the results of the CTEs?
; WITH maxes AS
(
SELECT DISTINCT
e.EventID,
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
SELECT count(*) FROM maxes
; WITH maxes AS
(
SELECT DISTINCT
e.EventID,
--FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
SELECT count(*) FROM maxes
-- Same number (5).... Next...
-- 6. Second check: check the name of the columns in the CTEs, maybe a ',' or something is missing
-- No... Next...
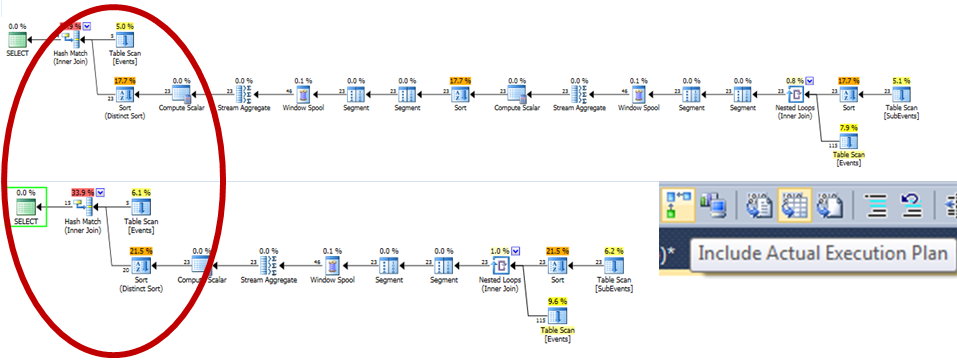
-- 7. Third check: check estimated execution plan
; WITH maxes AS
(
SELECT DISTINCT
e.EventID,
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
SELECT *
FROM dbo.Events e
JOIN maxes ON e.EventID = maxes.EventID
WHERE e.LastSubEventID <> maxes.maxEventId_ExecDate
; WITH maxes AS
(
SELECT DISTINCT
e.EventID,
--FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
SELECT *
FROM dbo.Events e
JOIN maxes ON e.EventID = maxes.EventID
WHERE e.LastSubEventID <> maxes.maxEventId_ExecDate
looks pretty similar (except the one more FIRST_VALUE componenets)
BUT: look at the estimated numbers in the left side of the plan - they are not the same...
And in my real case:
Finally - we have a clue...!
-- 8. Let's check actual execution plan
Plus-minus the same as the estimated....
-- 9. Forth check: Start look at the data
40,000 records, but I had no other choice...
-- let's take the CTEs to temp tables and check them:
SELECT DISTINCT
e.EventID,
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
INTO #tmp2first_value
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
SELECT DISTINCT
e.EventID,
--FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc) AS [maxEventId_ExecDate]
INTO #tmp1first_value
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
-- run selects:
select count(*) from #tmp2first_value --5 (in my "real" case there were 1,183,399...)
select count(*) from #tmp1first_value --5 (in my "real" case there were 1,183,399...)
select * from #tmp2first_value f2 join #tmp1first_value f1 -- 4 (in my "real" case there were 1,146,427...)
on f2.EventID = f1.EventID and f2.[maxEventId_ExecDate] = f1.[maxEventId_ExecDate]
select EventID ,[maxEventId_ExecDate] from #tmp2first_value
except -- 1 (in my "real" case there were 36,972...)
select EventID ,[maxEventId_ExecDate] from #tmp1first_value
-- now I took one example:
select * from #tmp2first_value where EventID = 4
select * from #tmp1first_value where EventID = 4
--> DIFFERENT [maxEventId_ExecDate] !!!!!!!!!!!!!!!!!!!!
We have a reason to the different results, now we need to find:
1. An explanation
2. Which one is the correct one?
3. A solution (to be sure that all of the 40000 will be correct).
SELECT * FROM dbo.SubEvents WHERE EventId = 4 ORDER BY CreateDate DESC
CAN YOU SEE THAT??
ExecDate is the same for all of the records.
--> Any one of them can be the result of the query of the "max" of them, so the result can be different!
--> 1. We have an explanation!
2. which one is the correct one?
--> For the query - all of them...
The answer for that it's a logic/bisiness/app answer: can be by the CreateDate, SubEventID, ..... etc.
3. A solution (to be sure that all of the 40000 will be correct)
What we have?
A case that all of the ExecDate were the same, so in 2 selects we had different ordering --> different results!
The solution is to specify an exact ordering (acording to the logic/bisiness/app answer that we've got).
Here it looks logicaly to add the CreateDate or the ID (SubEventID) to the ordering.
I'll take the ID (desc) - in order to do the example more clear
* ID can be better if the CreateDate can also have duplications!
* Of course it will be smart to do a specific ordering in all FIRST_VALUE.
SELECT DISTINCT
e.EventID,
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc, SubEventID desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc, SubEventID desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
; WITH maxes2first_value AS
(
SELECT DISTINCT
e.EventID,
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc, SubEventID desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc, SubEventID desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
, maxes1first_value AS
(
SELECT DISTINCT
e.EventID,
--FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.CreateDate desc, SubEventID desc) AS [maxEventId_CreateDate],
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc, SubEventID desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
select EventID ,[maxEventId_ExecDate] from maxes2first_value
except --0 records (also in my "real" case)
select EventID ,[maxEventId_ExecDate] from maxes1first_value
-- and - what we REALY need to update?
-- now join them to the event table and select only the required results:
; WITH maxes AS
(
SELECT DISTINCT
e.EventID,
FIRST_VALUE(s.SubEventID) OVER (PARTITION BY s.EventId ORDER BY s.ExecDate desc, SubEventID desc) AS [maxEventId_ExecDate]
FROM dbo.Events e
JOIN dbo.SubEvents s ON e.EventID = s.EventId
)
SELECT *
FROM dbo.Events e
JOIN maxes ON e.EventID = maxes.EventID
WHERE e.LastSubEventID <> maxes.maxEventId_ExecDate
Summary, Conclusions and Insights
Actually, in my "real" case, I select the spare FIRST_VALUE just to "get a feeling" of the data.
In the end - it was helpful for me to catch this case... (and, actualy, to prevent errors...).
Why the ordering was different?
Because in each table the table was scaned by a different column: ID of CreatedDate that was sorted for the FIRST_VALUE
Conclusions:
1. Ordering must be exact and untrusted by fate
a. Wrong data
b. Missing or surplus data
c. Logicaly is more correct
2. Test data before run an update script! (supposed to be obvious, but you know..... ;) )
-- Cleanup
DROP TABLE #tmp2first_value
DROP TABLE #tmp1first_value
DROP TABLE dbo.Events
DROP TABLE dbo.SubEvents